


When was the last time that you tried to setup replication between S3 buckets? It is not an easy thing to do as it often results in the chicken & egg problem. When you are configuring replication on your bucket, the other bucket has to exist. You might think of one solution to deploy your stack multiple times, first creating all the buckets followed by adding the replication. However, this is a bad practice! You should always be able to redeploy your CloudFormation stack from a clean state without tampering with it!
Why should you need S3 replication?
S3 replication is beneficial for multiple reasons. You can use it for disaster recovery to have the same content in a bucket as in another region. When for instance using a failover architecture.
Another reason is to copy data to another bucket and have an isolated process running on the data. An example of this could be that you have a Lambda function that listens to S3 events and does some processing for you. One is the reasons why you would do this could be to maintain the data under another ownership.
You can find some other use-cases in the AWS documentation here.
We need something better
I've created a plugin for the serverless framework which helps you with all these issues. It's called serverless-s3-replication-plugin and gets executed after your CloudFormation stack update is complete. This way, it can detect if all required S3 buckets exist and only then proceed with the replication setup.
A bonus is that the plugin also handles creating the right IAM roles for you, of course, while keeping the least amount of privilege principle in mind.
How to use the plugin?
To start using the plugin, follow the following steps in your repository assuming that you are already using the Serverless framework:
-
- Download the plugin from the npm registry with npm install --save-dev serverless-s3-replication-plugin
- Configure your
serverless.ymlconfig file to use the plugin in the plugin section, for example: ```yaml plugins: - serverless-s3-replication-plugin ```
- Configure which kind of replication you want, as is further explained in the next section.
Different kinds of replication
One-way replication
One-way replication is the most straightforward form of replication. A bucket replicates its content to another bucket, but not vice versa
Example configuration:
custom:s3ReplicationPlugin:singleDirectionReplication:- sourceBucket:eu-west-1: my-bucket-jlsadjklsd-eu-west-1targetBuckets:- eu-west-2: my-bucket-jlsadjklsd-eu-west-2- eu-west-1: my-bucket-jlsadjklsd-sec-eu-west-1- sourceBucket:eu-central-1: my-bucket-jlsadjklsd-eu-central-1targetBuckets:- eu-west-1: my-bucket-jlsadjklsd-eu-west-1
Two-way replication
Then there is two-way replication, which you could use within a disaster recovery architecture with a fail-over mechanism. After recovery, the two buckets should be in sync to proceed with normal behaviour when the primary region is recovered.
Example configuration:
custom:
s3ReplicationPlugin:
bidirectionalReplicationBuckets:
- eu-west-1: my-bucket-jlsadjklsd-eu-west-1.
- eu-central-1: my-bucket-jlsadjklsd-eu-central-1
- us-east-1: my-bucket-jlsadjklsd-us-east-1
Hybrid replication
With hybrid replication, I mean that you are mixing one-way replication with two-way replication. You might need something like this in more complex architectures.
A scenario where you could possibly use this is when you have an application deployed in two regions. Both regions are actively being used and the traffic of the application should be redirected to the other region in case of a disaster. To be able to keep on running the data from an S3 bucket should be always be replicated to the other region. Until here we have two-way replication. There is another team that is only interested in data from 1 region. For that reason, they have one-way replication from the bucket in the region they are interested in.
If you take a look at the picture below, it is good to know that data that is being replicated from Bucket B to Bucket A, doesn't get replicated further to Bucket C.
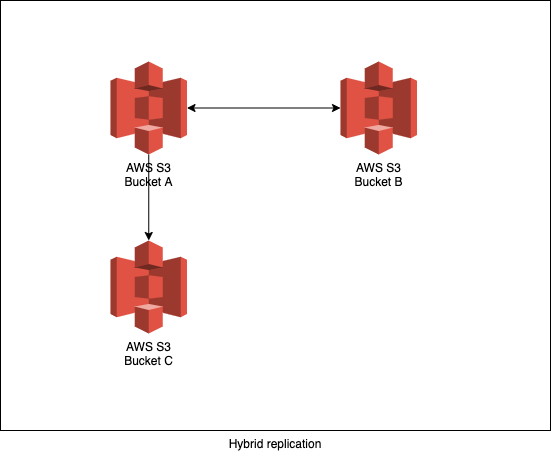
Example configuration:
custom:s3ReplicationPlugin:singleDirectionReplication:- sourceBucket:eu-west-1: my-bucket-jlsadjklsd-eu-west-1targetBuckets:- eu-west-2: my-bucket-jlsadjklsd-eu-west-2- eu-west-1: my-bucket-jlsadjklsd-sec-eu-west-1- sourceBucket:eu-central-1: my-bucket-jlsadjklsd-eu-central-1targetBuckets:- eu-west-1: my-bucket-jlsadjklsd-eu-west-1bidirectionalReplicationBuckets:- eu-west-1: my-bucket-jlsadjklsd-eu-west-1- eu-central-1: my-bucket-jlsadjklsd-eu-central-1- us-east-1: my-bucket-jlsadjklsd-us-east-1
S3 replication and S3 events
When using S3 replication with S3 events, you should be aware that if something gets replicated to another bucket, that it will also trigger an S3 event also in the destination bucket.
This could lead to processing items multiple times. Suppose you want to avoid that, you could check the principal of the event. It shows you who created the event so that you can adjust the event "processing" logic as/if required.
The end!
Hopefully, this is the end of painful S3 replication setups and the repetitive work that comes with them.
Feel free to contribute or request additional features if you feel that the plugin is missing anything or can be improved.
Github: https://github.com/stefmorren/serverless-s3-replication-plugin
Npmjs: https://www.npmjs.com/package/serverless-s3-replication-plugin


