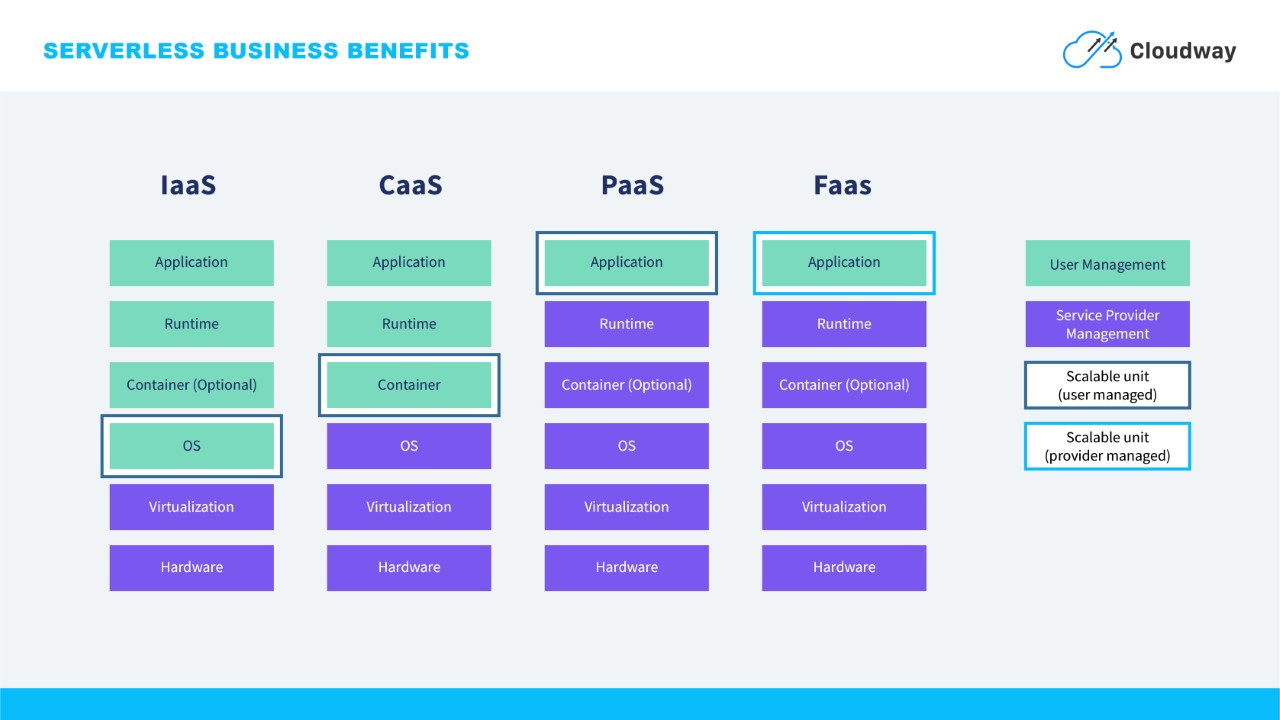
At Cloudway we are big believers in the serverless model and that's why we want to highlight how this model gives us a lot of flexibility. Here we want to focus on the flexibility to pick the (serverless) services we need for each use case, while using any of the meriad of available tools to ensure - eventual - consistency of the entire application at scale.
As a decision maker in the technology strategy, we want to show you how a serverless mindset can help you bring value to your customer in your new ventures or products as well as in your existing markets and customer solutions. In this blog we'll highlight how leveraging serverless technologies can help you focus on the business that your customers expect, in code as well as in effort. We'll show how an event-driven approach can create a near real-time application while making use of several public cloud serverless services helping you bring value to your customers.
At Cloudway, we don’t like to reinvent the wheel. Therefore, we strive to use the "Buy before Build" approach. With this approach we use the functional and non-functional requirements of the project to research products and/or services that are able to handle specific parts of the application and focus on how these different products/services can be tied together to achieve the requested result.
An example of this would be integrating the services of an OAuth provider to ensure secure authentication and authorization of the application that needs to be build. This also allows us to focus development on the parts of the application that create real business value.
However, there are a few challenges in using the "Buy before Build" approach. When designing your application using 3rd party products and services, it is necessary to make sure these products and services interact with each other correctly. This often means that there is need for small middleware or some glue services to transfer events and data from and to these 3rd party products and services. Preferable, near real-time.
Near real-time and event-driven architectures
This near real-time middleware is only one of the near real-time requirements that companies face today. The aim while building these type of middleware systems is merely to make sure data is consistent over the landscape of your company and to give a unified customer experience. Other possible requirements might be that customers expect to be notified near real-time, your marketeers want to get more from customer touchpoints, the digitalization brings security challenges which need near real-time analytics as everything becomes connected.
Often there are also business requirements for near real-time processes. For example, a marketeer might want to update their product content on a plethora of channels and they might require the new info to be deployed fast and consistently over all channels. For these reasons, companies are moving away from a batch and time-based processing approach.
Such near real-time requirements often need event-driven systems in order to support both fast handling of single events but also the scale needed to reliably handle a high throughput . Serverless technologies were created with this event-driven approach at its core. On a technical level, serverless functions (also called Functions-as-a-service or FaaS) are the glue between the different services of the cloud provider. For example, in serverless systems, uploading a file or inserting a record in a database, will generate an event. This event can in turn trigger a function which can process, analyze and/or act upon (the data in) an incoming event in near real-time.
Functionally, these are not new concepts, database and storage triggers have existed for a long time, however, serverless functions enable these concepts and technologies to run in a highly distributed and large scale environment. Moreover, the heavy lifting of operating and maintaining the infrastructure required for these highly distributed and large scale environments is done by the cloud provider. This makes it easy to set up an event-driven system that can process events in parallel on an architecture level, without the need for managing the scaling on an infrastructure level. Thus, making the performance reliable and offering the best throughput time requiring little effort.
Even though event-driven applications are a good fit for a lot of use cases in order to provide fast responses and a unified experience for all users, as with all other technologies and paradigms, it has unique challenges to overcome.
A couple of these challenges are: * Unpredictable spikes in load * Tracing of the events from the source of the event throughout the entire system * Parallel and distributed processing
Luckily, since we follow the "Buy before Build" approach, we can leverage the serverless services provided by the public cloud providers to mitigate some - if not all - of these challenges. Since serverless functions and other serverless technologies were created with this event-driven approach in mind, they provide solutions for parallel processing of events at any scale because they are backed by the server capacity of the cloud providers and they auto-scale which helps mitigating any unpredictable spike in the load on the application. In more recent years, a lot of development has been done by the cloud providers in order to allow for easier and better tracing of the events, but there's also numerous third party tools providing monitoring for a serverless application, such as Lumigo and Thundra.
Extensibility and continuous improvement
The serverless event-driven approach not only allows for good scalability and virtually limitless parallelism, it also helps in designing a loosely coupled system. This in turn hugely benefits the extensibility of the application in order to support new workflows quickly and easily, but also allows for evolution of some parts of the application, while other parts don't need to be touched nor deployed for the new improvements to benefit the users of the application.
On top of this, the public cloud providers accomodate and promote the use of infastructure-as-code (IaC). This allows the users to describe the entirety of the (serverless) application in a text or code format and include this in the versioning system of choice. This also brings the infrastructure closer to the developers which in turn can be used to increase the level of continuous improvements not only for the code that is deployed, but also for the configuration of the cloud infrastructure.
As an example of all this, let's take the IoT Telematics insurance platform we've designed an build as a high throughput serverless event-drive system. For this platform, we needed to ingest and enrich telematics data from a car. Communication happens using the MQTT protocol and incoming messages will trigger serverless workflows that handle the real-time processing of the data. And since we are using serverless technologies, it means that ingesting and enriching the trip data which comes from the car can happen in parallel, regardless of whether we have 5 or 5000 trips happening at the same time. Since each trip is processed in its own workflow hosted on its own infrastructure (by the cloud provider), they all are processed within the same time frame.
Because of this event driven approach and the glue provided by serverless functions, it is easy to get the full benefit of the eco-system of the cloud provider. It allows us to pick the tools and technologies that match the use case, instead of trying to match the use case to the preferred technology. In this case, the requirements were heavily focussed on writing data to a data storage with a very high throughput, while the data retrieval requirements were not high throughput and mostly concern doing advanced searches. The event-driven approach allowed us to separate these read and write requirements by using two different data stores, one optimized for writing and one optimized for searching. Synchronizing the data between the two data stores happens in a near real-time and event-driven way using serverless functions and some little glue code.
If you've got questions after reading this blog or if you simply want to know more about serverless or about Cloudway, do not hesitate!
Contact us